
中外大厂、初创公司都头好秃,全被追着问:你们对DeepSeek怎么看? DeepSeek出来你们怎么办?
国内,比如腾讯,昨天刚刚在微信开启灰度测试“AI搜索”功能,接入的就是DeepSeek-R1;比如百度,当即宣布4月起文心一言免费用,下一代文心模型决定开源……
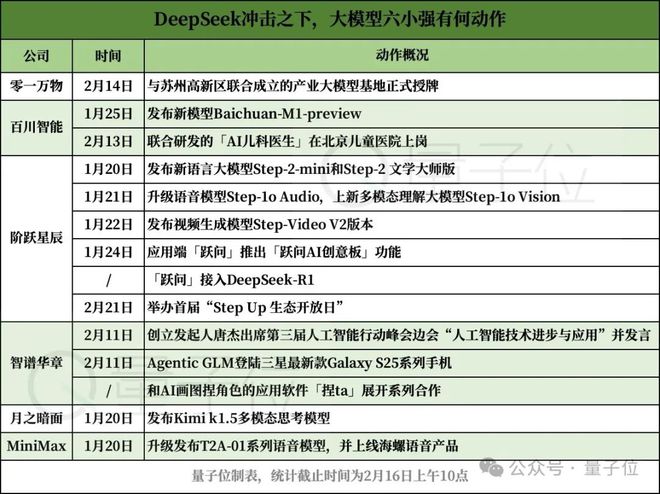
六家已成为独角兽的大模型创业公司,零一万物、百川智能、阶跃星辰、智谱华章、月之暗面、MiniMax江湖人称大模型六小强。
但这不代表它们没有行动——毕竟比起高谈阔论,落地的实际行动更值得用来证明。
DeepSeek-R1问世之前,创始人李开复博士已公开表示,零一万物将不再追求训练超级大模型。
经过为期半年多的探索验证,他们明确表示,参数适中同时性能优异、推理速度更快、推理成本更低的轻量化模型更适合商用场景,“会成为AI-First应用爆发的催化剂”。
而DeepSeek问世之后,零一万物对外曝光的首个动作,选择了携手苏州——
该大模型基地聚焦垂直产业,重点打造制造、金融、医疗、政务、生物、具身等多个领域的行业大模型解决方案,联合产业链上下7家企业,“探索大模型技术从实验室走向生产线的产业化路径”。
在现场,李开复谈道,在人工智能技术重构产业的关键节点,大模型绝非“空中楼阁”,而是驱动实体经济的核心引擎。

继1月2日与阿里云联合成立“产业大模型联合实验室”之后,零一万物再度于产业大模型方向落子。 此次于苏州高新区落地的“产业大模型基地”进一步加速了零一万物模型能力商业落地的进程。百川智能
这是百川第一个全场景推理大模型。所谓全场景,指的是该模型同时具备语言、视觉和搜索三个领域的推理能力。
Baichuan-M1-preview解锁了医疗循证模式,官方解释它“实现了从医疗证据检索到深度推理的完整端到端服务,能够快速、精准地回答医疗临床、科研问题”。
2月13日,以Baichuan-M1为底座打造的「AI儿科医生」经过近一个月的内测后,在京“上岗”。
针对临床推理,它首先会基于一诉五史生成诊疗假设,继而通过检验检查数据进行假设证伪与排除,最终经由自反思机制对剩余假设进行概率排序,输出符合临床思维路径的诊疗建议。
官方消息显示,当天,北京儿童医院开展了国内首次“AI儿科医生+多学科专家”的双医并行多学科会诊。与会人员除了多科室13位专家,还有该医院与百川智能、小儿方健康科技(这家是百川投资的医疗数据公司)联合研发的「AI儿科医生」。
与会者对一位颅底肿物伴随 抽动症状的患儿进行了多学科会诊,另一边,工程师将患者的主诉和病历资料输入模型。

1月20日当天发布的两款模型均为语言模型,一款是轻量级、响应快、性价比高的Step-2-mini,与自家模型玩意参数的Step-2相比,Step-2-mini以3%左右的参数量保有80%以上的性能。
21日,升级语音模型Step-1o Audio,又上新多模态理解大模型Step-1o Vision。后者发布首测就冲上来了大模型竞技场前10,位列视觉领域国产第1。
22日,发布视频生成模型Step-Video V2版本,该版本在前代V1基础上,从VAE模型、DiT架构与RL融合、多模态大模型应用三方面基础上升级而来。

模型侧更新外,阶跃星辰旗下应用「跃问」也在1月24日推出了全新功能,跃问AIKaiyun平台 开云体育官方入口创意板。
它的功能是“不用代码就能在3步内实现想法,开发应用”,并且将成果全平台分享。
BTW,量子位发现,跃问不知何时已经偷偷接入了DeepSeek-R1……
以及农历新年前频繁动作之时,阶跃星辰系统负责人朱亦博就在朋友圈小小剧透,年后阶跃有大动作。
而“大动作”本身,或许会在2月21日阶跃星辰举办的首届“Step Up 生态开放日”上揭晓。至于有无针对DeepSeek-R1的回应性动作或战略,也要等到下周会上才见分晓了。
2月11日,清华大学计算机系教授、智谱创立发起人唐杰在巴黎大王宫举行的第三届人工智能行动峰会边会“人工智能技术进步与应用”上发言。
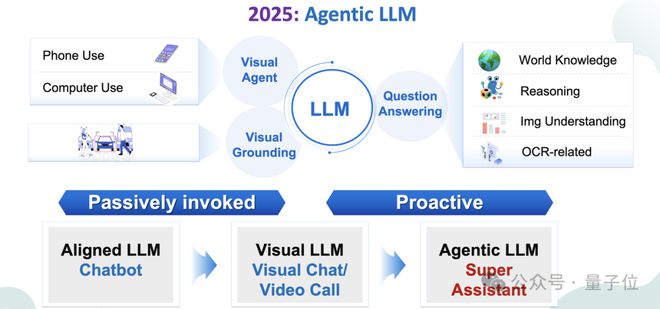
在阐述对AGI的5个阶段划分后,唐杰表示现在正处于L2和L3交汇处,即“对齐机器与人类的意图”和“机器自我学习”的交汇处。
自主的、具有Agent能力的大型语言模型(Agentic LLMs)将成为日常生活和工作的核心。
通过给定高层次目标,自主的LLMs将制定计划、利用数字设备并执行复杂项目,而所需的人类干预极少。
这些自主系统将不再仅仅是孤立的实体,而是将协同工作,互补优势,以更高效地完成任务。
此外,面对DeepSeek搅动风云,智谱的“回应”更多落实在开年频频落地上。
具体表现为让Agentic GLM(智谱专为手机研发的系统级大模型)登陆三星 最新款Galaxy S25系列手机,提供基于AI的实时语音和视频通话,以及实现视觉理解和系统功能调用、AI搜索、文案写作等功能。
其次是量子位注意到,虽未对外官宣,但智谱近日悄悄开始和二次元很火热的AI画图捏角色的应用软件「捏ta」展开合作。
一方面,智谱在自家视频模型上线了捏ta;另一方面,二家基于智谱的CogVideoX-2模型等,在捏ta发起联名活动。
你说巧不巧?DeepSeek-R1发布一个半小时后,月之暗面官方公众号宣布了旗下Kimi k1.5多模态思考模型。
k1.5团队将RL的上下文窗口扩展到128k,背后的一个关键思想是使用部分展开(partial rollouts)来提高训练效率。
k1.5团队推导出long-CoT的RL公式,并采用在线镜像下降的变体进行稳健的策略优化。
上述二者的结合为通过LLMs学习简历了一个简洁的RL框架,最终实现在不依赖蒙特卡洛树搜索、价值函数和过程奖励模型等情况下实现更强性能。
2月12日,OpenAI展示o3轻松拿下IOI 2024金牌的那篇最新报告论文中,介绍部分就提及了DeepSeek-R1和Kimi k1.5分别通过CoT提升大模型在数学和编程上的性能。

升级发布T2A-01系列语音模型,并上线了海螺语音产品(同样兼顾模型与产品的推动)。
T2A-01系列包含T2A-01-HD、T2A-01-Turbo两款模型,API服务同步上线MiniMax开放平台。该系列模型支持17种语言及上百种预置音色。
依托该系列模型,在海螺AI,用户仅需输入文字即可生成自然、流畅的超拟人人声,最长可输入多达10000字符。且可根据需要自由配置输出语音的情绪、语速、音高,甚至调整音色效果。
这里特别提及一个1月20日前发生的事情,那就是1月15日,MiniMax创始人兼CEO闫俊杰对谈《晚点》稿件发出,其中展示和透露出MiniMax在当时对2025年的调整和计划。
这一点呼应了当日MiniMax官宣MiniMax-01系列模型,且发布即开源。
当然了,DeepSeek这头深海巨鲸此次扔出R1,搅动的不仅仅是国内六家大模型独角兽的圈子。
也就是说,放眼Kaiyun体育官方网站 开云登录网站国内,被冲击的不只是六小强,没有一家科技巨头或AI大模型公司置身事外。
譬如DeepSeek「大胆启用业界经验不够丰富的年轻技术人才,以此作为追求突破性技术创新一环」的故事,就在街头巷尾广为流传,重新叩问了每一个企业对用人标准的定义。
譬如百度,在放出宣布文心一言即将免费的消息后,紧跟着宣布了决定背叛闭源大模型的决定——将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。
在被问到DeepSeek是否是意料之中时,李彦宏也在日前的迪拜AI峰会上坦言:
我认为,创新是不能被计划的。 你不知道创新何时何地到来,你所能做的是,营造一个有利于创新的环境。
云计算厂商和AI Infra平台/公司,第一时间上线DeepSeek API,不仅陆续搭载上671B满血版,还争相优化截断率、回复速度、准确率等等,有的还推出利好本地部署的框架,再破大模型推理门槛。
为涌入巨量用户的DeepSeek分流,让更多用户从不同渠道把AI用起来。
另一边,以腾讯为例,从云平台腾讯云、腾讯云旗下大模型知识应用开发平台知识引擎、国民应用微信、AI智能工作台ima、主力AI应用元宝全方位拥抱DeepSeek,纷纷宣布接入R1模型,还用自身能力为其使用体验添砖加瓦。
它们开放兼容,拥抱的不光是DeepSeek,更是用户体验最佳的模型——不管是否是“纯自研”。

放眼国际,DeepSeek的名字已经成为华尔街分析师会议上最高频提到的AI公司。
随着Alphabet(谷歌母公司)、AMD、Palantir和亚马逊等科技巨头公布收益,DeepSeek被提及的次数还在增长。

具体到国外大模型玩家身上,面对“DeepSeek冲击波”,有急得跳脚的,也有反思与撷取精粹的。
OpenAI,紧急地首次向用户免费推出推理模型o3-mini,CEO奥特曼还在Reddit“有问必答”活动中罕见公开反思:
OpenAI现在已经能在一日之内连续官宣GPT-4.5几周内上线几月内面世,以及关于模型路线规划调整、既有模型迭代更新的多个新消息。
而在大模型赛道之外,DeepSeek冲击带来的影响力如何,大家肉眼可见——
据不完全统计,目前接入DeepSeek模型的第三方,包括infra平台、手机厂商、Web/App应用、智驾终端等在内,已超百家。
GitHub上,V3/R1不断攀升的星标数量,代表着更多人可以把DeepSeek用起来。
由是深海巨鲸向AGI更深处求索,丢下R1这枚深水炮弹后,坊间开始流传一个新梗。