
在全光线路交换(OCS)互连的全光网络支持下,分解式网络为人工智能和机器学习开云网址 kaiyun官方入口带来全新网络设计。
云计算领域的超大规模企业和其他高性能计算 (HPC) 服务提供商必须构建和拓展其计算平台,以满足客户对人工智能应用的需求,同时控制资本支出并降低能耗需求。特别是,所需的处理能力已经提高了几个数量级。
不同于将这些平台的构建块紧密地、但不灵活地捆绑在一个相对单一的平台(如标准服务器机箱)中,而“分解”必要的组件或子系统的过程避免了效率低下和一些关键底层资源利用率不足的风险,更重要的是,如果简单地 “架设和堆叠”更多服务器,则不可避免地出现过度地能耗。
在分解式架构中,这些资源(CPU、内存、存储、各种形式的加速硬件)使用集成式高速数字收发器和基于适当传输介质和交换技术的专用互连结构进行互连,因此实现了灵活的组合。资源可以相互独立地组合和适当扩展,满足预期工作负载的需求。
资源分解原理如上图所示。利用底层细粒度资源的公共池,所需资源以定制比率捆绑在一起,动态“组合”形成占比灵活的“裸金属主机”硬件主机。在这种情况下,关键构建块是低级别的资源元素本身,例如 CPU、内存、存储和各种加速器(GPU、TPU、FPGAs)。
就可访问和可消耗的资源块的细粒度,可以定义不同的分解级别。
在细粒度最高的分解形式中,每个资源块(例如一组 DRAM、一个 CPU、一个加速器)都拥有板载硬件,以便于其资源与互连平台进行必要的高速、低延迟连接。
细粒度稍低的资源分解形式与当前硬件实施更加兼容,可被视为促进向完全分解平台渐进过渡的一种方式。其中包括:覆盖在分组交换结构上的光互连和改变传统服务器的用途。
在这种应用中,动态互连的计算资源组件仅限于加速器硬件。通过单模光模块,它们可以使用专用光交换结构,灵活、直接地与其他主机中的同类组件互连,该专用光交换结构有效地叠加在包交换网络上,这些包交换网络已经将集群中主机之间互联起来。
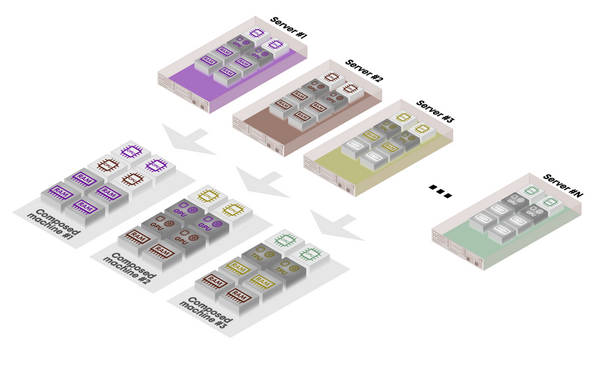
除单独对加速卡进行互连外,还可以访问传统服务器群中已经存在的更多资源,配备专业的 SerDes 处理硬件和固件以及高密度、高速光收发器的专用 PCIe 互连卡充当机箱中与 PCIe 连接的计算资源和光互连结构之间的高性能网关。
这是一种采用透明全光线路交换的光互连结构,该结构提供了确定性、线路交换的固定带宽数据路径,非常适合硬件资Kaiyun体育官方网站 开云登录网站源地互连,否则这些硬件资源将通过服务器主板上的专用线路或者PCI Express 等特定总线直连进行固定的低级互连。
与电交换网络相比,它还能够大幅降低网络本身的功耗,显著降低与数据路径相关的延迟,以及更好地对网络架构进行纵向和横向扩展。由于全光交换网络对与分解式资源元素相关联的光收发器之间的序列化数据流量的格式和线路速率具有固有的透明性,因此面为未来带宽升级更加友好。

全光交换机等损耗最低的全光线路交换机允许用多达四级或四级以上的交换来构建网络架构,同时保持在使用分解式资源元素的典型光收发器的光损耗预算之内。
可将平台扩展到适合在硬件运行的各种工作负载的可用资源类型的任何大小和比率。
在运行特定工作负载的过程中,可以随资源消耗需求的变化调整平台的大小。
可以暂时关闭不需要的资源,节省运营开支 (OPEX)。